在现代计算机系统中,分布式、高并发和多线程是三个常见但容易混淆的概念。它们各自关注不同的层面,但在数据处理和存储服务中协同工作,共同支撑高效、可靠的应用系统。
我们来明确这三个概念的定义和区别:
- 多线程(Multithreading):
- 多线程是指在单个进程内,通过创建多个线程来并发执行任务的技术。每个线程共享进程的内存空间,但拥有独立的执行路径。
- 核心目标是提高单个节点的资源利用率,例如通过并行处理减少CPU空闲时间。
- 例如,在一个Web服务器中,多线程可以同时处理多个用户请求,避免单个请求阻塞整个服务。
- 高并发(High Concurrency):
- 高并发描述的是系统在单位时间内能够同时处理大量请求的能力,通常涉及用户访问量或任务数量的激增。
- 它不是一个具体的技术,而是系统的一种特性或需求。实现高并发往往需要结合多线程、分布式等技术。
- 例如,电商平台在双十一期间需要应对数百万用户同时下单,这就是典型的高并发场景。
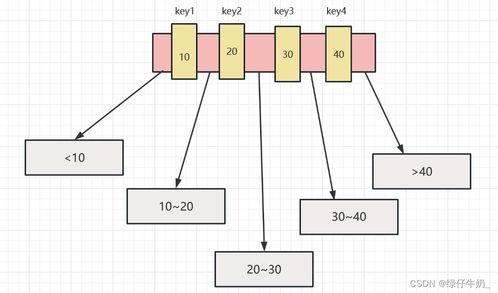
- 分布式(Distributed System):
- 分布式系统由多台计算机(节点)通过网络连接组成,这些节点协同工作,对外表现为一个整体。
- 核心目标是通过水平扩展提升系统的可扩展性、可靠性和容错能力。
- 例如,分布式数据库可以将数据分片存储在不同服务器上,以支持海量数据和高吞吐量。
三者之间的区别主要体现在:
- 关注层面不同:多线程关注单个节点内的任务并行;高并发关注系统整体处理能力;分布式关注多节点协作架构。
- 实现方式不同:多线程通过操作系统线程机制实现;高并发可通过负载均衡、缓存优化等策略实现;分布式依赖于网络通信和一致性协议。
- 规模与复杂度:多线程通常局限于单机;高并发可能涉及单机或多机;分布式必然涉及多机,复杂度更高。
在数据处理和存储支持服务中,这三者如何发挥作用?
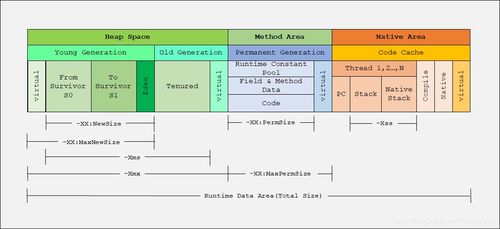
- 多线程的应用:在数据库或存储引擎中,多线程用于并行执行I/O操作、查询处理和事务管理。例如,MySQL通过多线程处理连接请求,提升响应速度。
- 高并发的支持:数据处理服务通过优化锁机制、使用异步I/O和连接池等技术来应对高并发。例如,Redis利用单线程事件循环避免竞争条件,同时通过集群模式支持高并发访问。
- 分布式的实现:分布式系统如Hadoop HDFS或Google Spanner通过数据分片、副本复制和分布式一致性算法(如Paxos、Raft)来提供高可靠和可扩展的存储服务。它们能够将负载分散到多个节点,避免单点故障。
实际应用中,这三者常常结合使用。例如,一个分布式数据处理平台(如Apache Spark)可能在每个节点上使用多线程执行并行计算,同时整个系统设计为支持高并发用户查询,并通过分布式架构实现水平扩展。
多线程、高并发和分布式虽然概念不同,但在现代数据处理和存储服务中相辅相成。理解它们的区别与联系,有助于设计出更高效、健壮的系统架构。