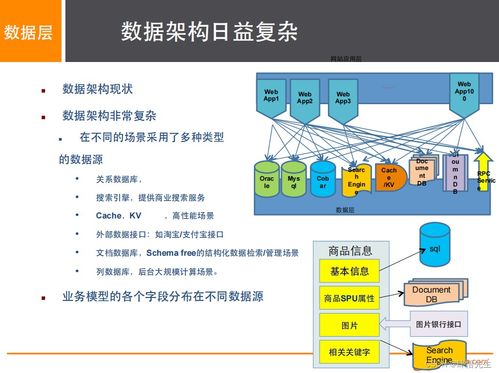
阿里巴巴作为全球领先的电商和云计算平台,其数据架构的演进历程为行业提供了宝贵的实践参考。随着业务规模的扩张和数据量的指数级增长,阿里巴巴的数据架构经历了从传统单体架构到分布式、云原生架构的全面升级。
在数据架构演进初期,阿里巴巴面临的主要挑战包括数据孤岛、处理性能瓶颈和存储成本高昂等问题。通过引入分布式计算框架如Hadoop和Spark,阿里巴巴实现了数据处理的横向扩展,显著提升了海量数据的处理效率。采用分层存储策略,将热数据、温数据和冷数据分别存储于高性能SSD、普通硬盘和低成本归档系统中,优化了存储成本。
在数据处理层面,阿里巴巴构建了实时和离线两套数据处理体系。实时数据处理依托Flink和Storm等流式计算引擎,支持秒级延迟的业务场景,如双11大促的实时监控和推荐系统。离线处理则通过MaxCompute(原ODPS)平台,实现TB级数据的批量计算和分析,为企业决策提供数据支撑。
数据存储支持服务方面,阿里巴巴推出了多种自研和开源解决方案。例如,分布式数据库OceanBase解决了高并发场景下的数据一致性和可用性问题;表格存储TableStore提供了海量结构化数据的低延迟访问;对象存储OSS则成为非结构化数据存储的首选。这些服务通过云平台对外输出,帮助众多企业降低了数据管理复杂度。
阿里巴巴的数据架构将继续向智能化、自动化和多云融合方向发展。通过集成AI技术,实现数据治理的自动化;借助云原生技术,提升资源弹性和运维效率。这一演进历程不仅体现了阿里巴巴的技术创新能力,也为全球数据架构实践树立了标杆。