在大数据技术体系中,HBase作为构建于HDFS之上的分布式列式数据库,其存储模型与数据处理机制是理解其高性能、高可扩展性的核心。本文聚焦HBase的存储模型及其为数据存储与处理提供的支撑服务,深入源码层面解析其设计思想与实现机制。
一、HBase存储模型解析
HBase的存储模型分为逻辑视图和物理存储两个层面:
- 逻辑视图:
- 表(Table):HBase中的数据以表形式组织,表由行和列组成。
- 行键(RowKey):数据的唯一标识,按字典序排列,决定了数据在Region中的分布。
- 列族(Column Family):一组列的集合,是物理存储的最小单元,必须在创建表时预定义。
- 列限定符(Column Qualifier):列族下的具体列,可动态添加。
- 时间戳(Timestamp):标识数据版本,支持多版本并发控制(MVCC)。
- 物理存储:
- Region:表按行键范围水平分割为多个Region,分布在不同RegionServer上,实现负载均衡。
- Store:每个Region按列族划分为多个Store,每个Store包含一个MemStore和多个HFile。
- HFile:底层存储文件,基于HDFS的序列文件格式,采用LSM树(Log-Structured Merge-Tree)结构优化写入性能。
二、数据处理与存储支撑服务
HBase通过多层服务架构保障数据的高效处理与持久化:
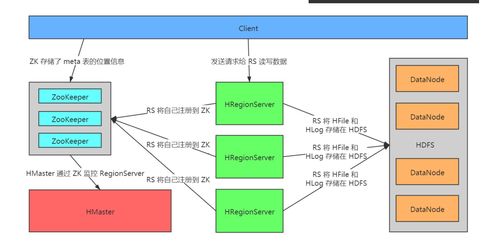
- RegionServer服务:
- 管理多个Region,处理客户端读写请求。
- 维护MemStore(内存写入缓冲区),当数据达到阈值时触发Flush操作,将数据持久化为HFile。
- 执行Compaction操作,合并小文件以减少读取开销,分为Minor Compaction和Major Compaction。
- HLog(WAL)机制:
- 通过预写日志(Write-Ahead Log)保证数据持久性,避免MemStore数据丢失。
- 每次数据写入先记录到HLog,再写入MemStore,支持故障恢复。
- BlockCache与Bloom Filter:
- BlockCache作为读缓存,缓存频繁访问的数据块,提升读取性能。
- Bloom Filter快速判断某行数据是否存在于HFile中,减少不必要的磁盘IO。
- 协处理器(Coprocessor):
- 允许用户将自定义逻辑嵌入RegionServer,实现轻量级分布式计算,如聚合、过滤等。
三、源码层面的关键实现
在HBase源码中,存储模型与处理服务的核心类包括:
HRegion:管理Region的生命周期与数据操作。HStore:负责单个列族的存储管理,包括MemStore与HFile的交互。HLog与WALEdit:实现WAL的写入与恢复逻辑。Compaction相关类(如DefaultCompactor):处理文件合并策略。
四、总结
HBase通过层次化的存储模型与多模块协同的服务架构,实现了海量数据的高吞吐读写与水平扩展。其源码中LSM树、WAL、缓存等机制的设计,为大数据的实时处理与存储提供了可靠支撑。后续文章将进一步解析Region分配、负载均衡等高级特性。